How to build a basic RAG
RAG answers queries from your documents by chunking, embedding, storing in a vector DB, retrieving matches, and feeding them to an LLM for context-aware responses.
Introduction
The Large Language Models (LLMs) are getting super efficient in performing wide range of tasks. But they are not trained on your own data so that they can answer questions from your data. This is where Retrieval Augmented Generation (RAG) comes into the picture.
RAG is a technique that allows LLMs to answer questions from your own data. At high leve, it involves two steps.
-
Indexing: We index our documents in a particular way so that we can retrieve the relevant information when we need it depending on the query.
-
Retrieval: We retrieve the relevant information from the indexed documents based on the query and pass the retrieved chunks to the LLM so that it can answer the question. This is like giving the LLMs context (from our documents) to answer the question.
Now, how do we index the documents? How do we query it? That's what we are going to see in this blog post. From implementation point of view it involves following steps
- Collect the documents
- Split into chunks and make vectors
- Query the top matching chunks
- Pass the chunks to the LLM
- LLM answers
I am going to dive deep into each step and explain how to implement it from a practical perspective. The focus would be to make a basic RAG setup for your documents and files in its simplest form. I will not be discussing much of code but will discuss the concept. Let's start with the first step.
Why not pass the document?
The first question you might ask is, why not just pass the entire documents (copy & paste) to the LLMs, ex: ChatGPT? There are multiple problems with this approach
- Generally we would have huge documentation about the company. Any LLM would have a fixed, for example
200,000tokens for the context window. It would easily eat it up very quickly - Just passing the entire document set as context does not make the LLM answer it accurately. LLMs often get confused if you pass irrelavent content. So, it is important to only pass the relevant content.
That doubt aside, lets move ahead!
Collect the documents
The first step is to collect the documents you want the LLM to refer from. You can consider all your company documents related to compliance, policies, procedures, on-boarding, etc. that are relevent for your use case. These documents generally should be in English unless the embedding model you are using supports other languages, which will be discussed later.
If your documents are in different formats such as videos, images, PDFs, etc., you need to convert them to text, preferrebly Markdown. There are multiple options to do this, while the popular one is markitdown from Microsoft.
Clean the documents
The next step in the process is to clean our documents by removing unnecessary content. For example, when you scrape a website you end up having a lot of junk in it for example the side menus, footers, navigations items etc. You need to make sure that your trim such contnet.
This is very important step. Remember:
Garbage in, garbage out!
This is the thumb rule while preparing the content. The AI answers will be degraded signifantly if you have garbage in your documents.
Pick embedding model & storage
This is a crucial step in the process. As mentioned above, we need to index our documents in a way that we can retrieve them when required. Let us take an example. Let's say we the below document among so many others
The maker of the app is Pramod
Now, we want this document to be retrieved when we as questions like Who is the founder? or Who is the person behind?. Now if you look the exact words, there is no relation. But as a human (someone who understands English) we know that the document is relevent to the questions. They are symantically related.
That means, we need a way to compare the Symantic features of the document and the query. This is exactly is called Embedding in this process. We take a pretrained (mostly on English) models and pass our documents individually, and get a feature set in result so that we store it a database and query the related documents with some mathamatical function later.
Let me give some names to the above mentioned terms that people use it in RAG workflow in general.
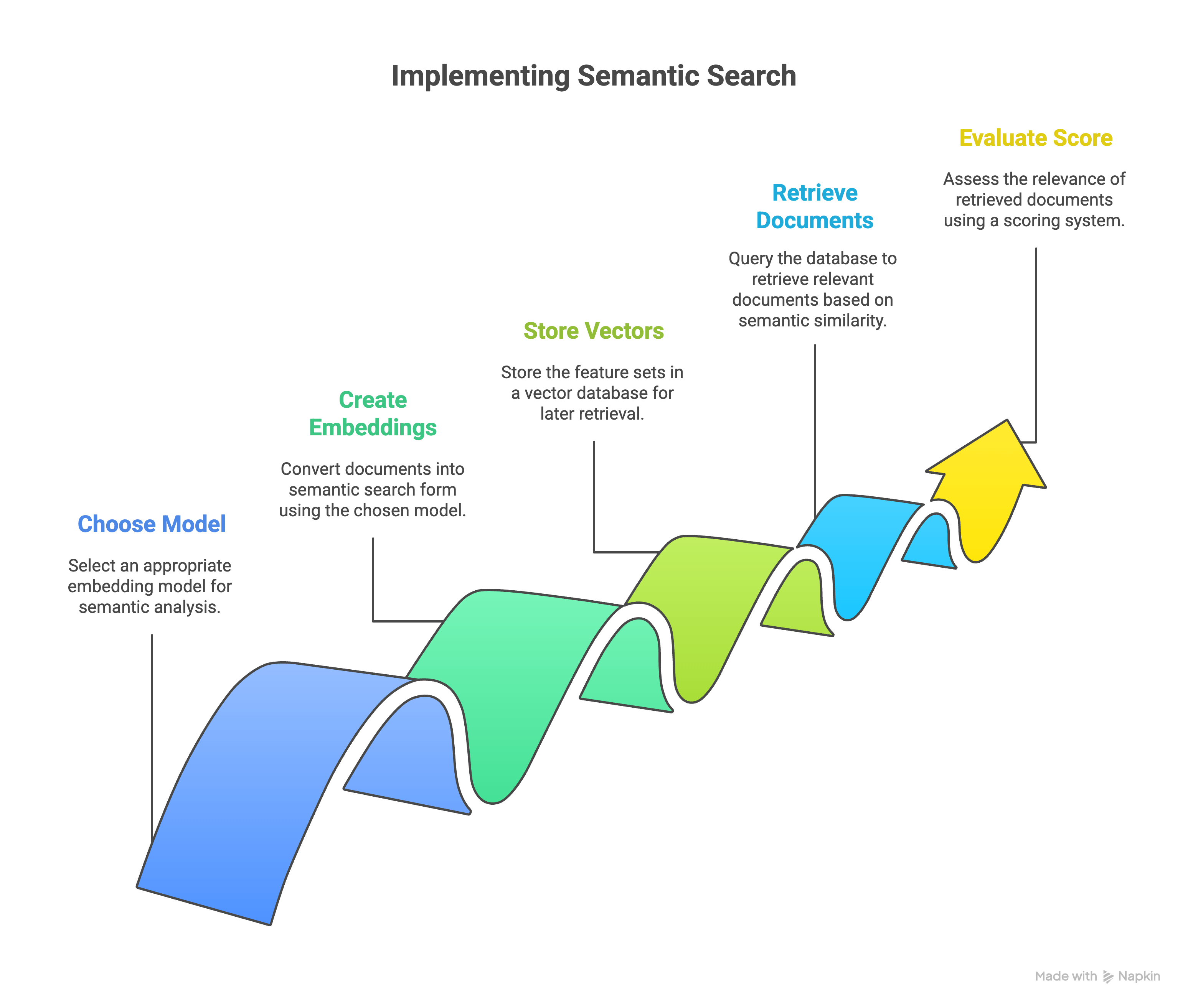
- Symantic search: the entire process of searching the documents based on the symantic meaning
- Embeddings: the documents that are turned into symantic search form
- Embedding model: the model that you use to make the embeddings. For example,
llama-text-embed-v2,multilingual-e5-large,pinecone-sparse-english-v0 - Vectors: the feature set that can be stored and can be used in a mathamatical function while retrieving. These are in general an array of numbers. These numbers represent the symantic nature of the input text. These are outputs of Embedding model
- Vector database: the storage where we store the vectors. Example
Pinecone,Postgres,MongoDB - Score: the storage system gives a score for the retrieved documents for the query provided
Pick the relavent Embedding model and the Vector database to proceed to next steps.
Chunking
Now that we have collected the documents, cleaned them up and picked the model and storages for the process, our next step is to generate the Vectors so that we can query the relavent documents. Wait, we still have an intermediate step to do.
Let us say we have 25 page document which discusses about FAQs about your company. Imagine we created a Vector array for this document. When we query the document there are multiple issues we get into
- The document is huge and when retrieved, it will quickly eat up our context window.
- As the document discusses about so many different concepts, the score it gets would be very low and that leads to poor retrieval quality
To fix these problems, we need to split the document into multiple chunks and then embed each chunk. Now, if the chunk is too small then we might miss out quality information after retrieval, if it is too large we get into above problems. So, we need to play around and figure out the size of the chunk.
Another importent point is to make these chunks contextual. Consider you chunked a section which talks about Customer onboarding, into two chunks. If the first chunk has the heading but not the second chunk, the score for the second chunk might get low. So, it is important to keep these chunks contextual.
To address this problem, CrawlChat maintains the chain of headings and table headings in all the chunks for better retrieval.
Create embeddings & store
Now we have so many chunks ready to turn them into embeddings. Now you can use the Embedding model to get the vectors. You can use their SDKs or APIs to do it. You might have to pay the providers for using these models.
The result of this step would the Vectors as mentioned above. As mentioned, a Vector is just a list of Float numbers. They desciribe the symantic nature of the chunk based on the used Embedding model. You can store this into a Vector supported storages such as Pinecone.
Make sure you also store the chunk text in either in the same vector storage or in a different database with maintaining some kind of Id so that we can retrieve the chunk text when Pinecone says chunk 123 is relavent.
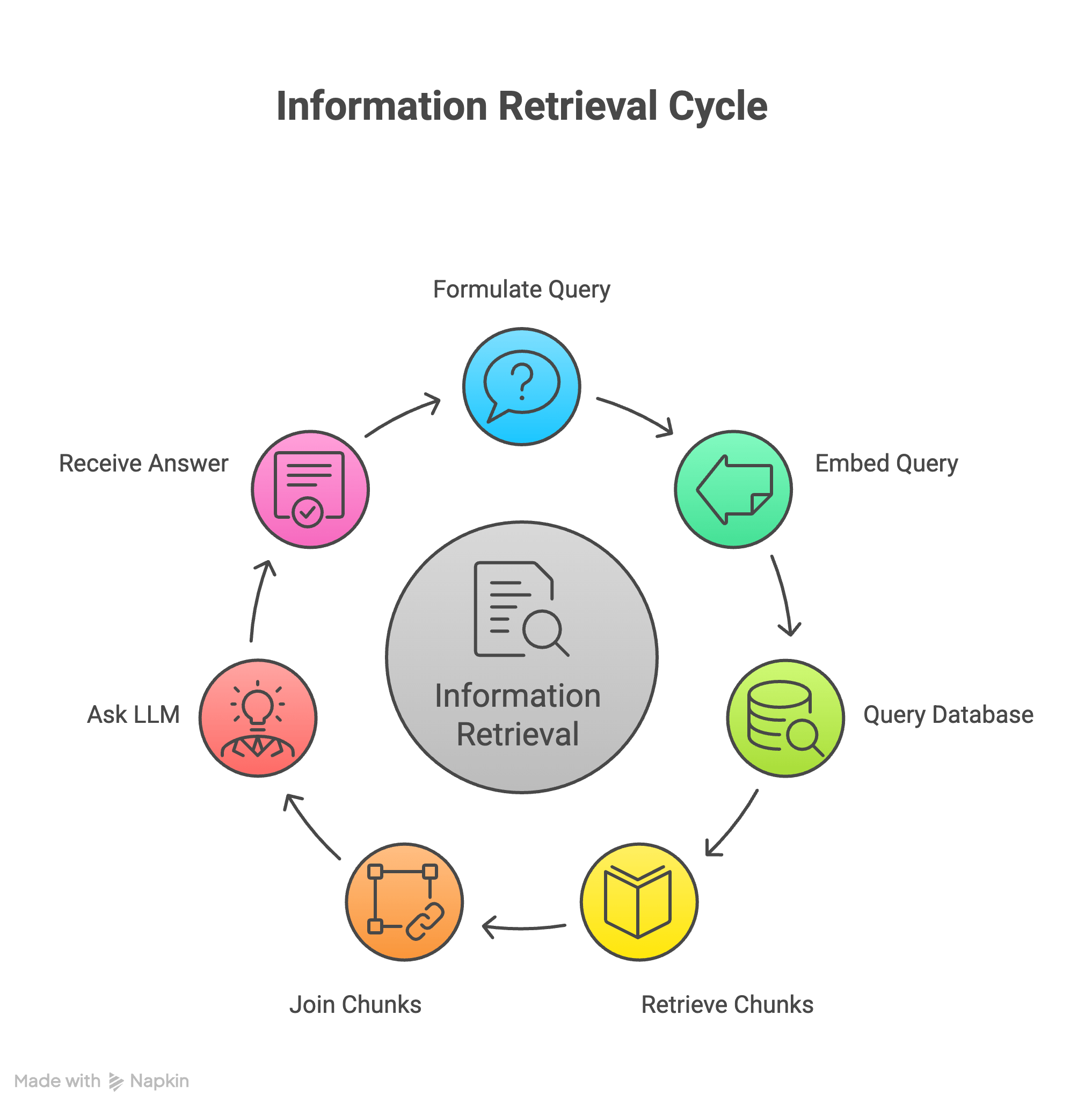
Query
There we just finished our first phase. We created chunks, turned them into vectors, stored them in a Vector database. Now we are all good to retrieve the relevant information for a given query.
Let's say you want fetch relevant chunks for quetion Who is the founder?. Here is how you do it.
- Create the vectors for the query as well.
- The Vector database provides query command (or API) where you pass the query vectors and gives back the records for the chunks that match the most.
Once you have the records that match the most for the given query, you need to fetch the corresponding chunk texts as well. As mentioned, if you stored it in the same Vector database, you might get it already or fetch it from different database and keep them ready for next step.
Pass to LLM
Now comes the easy step! We have the query and also the relevent chunks from our documents as context to answer the query. We can now happily pass these two informations to LLMs and ask it to answer the query.
Here is a psuedo code
const query = "Who is the founder?"
const queryVector = embedModel.embed(query)
const matches = vectorDatabase.query(queryVector)
const chunks = matches.map(match => db.find({ id: chunk.id }))
const context = chunks.join("\n\n")
const llmMessage = {
"role": "user",
"message": `Context: ${context}
----
Question: ${query}
----
Answer the question above withe the context provided
}
const answer = llm.ask(llmMessage)
Yay! We did it! AI answered the question by referring to our documents. That's the first step to more advanced workflows in RAG. Let's see how we can streamline this workflow in a better way.
Streamline
At highlevel, you already understood the core concepts of RAG. Try to grasp the core concepts. It is not required to solve it in a exact way. Once you understand the process, you can tweak each step or add more steps and make a better workflow for your use case. CarawlChat does a lot more than this to support wide veriety types of documents, and cater wide range of use cases.
The next step is to streamline the process. Here are few things that you can do to make it better
- Have utility functions to cleanup the documents based on the type of source or heuristics.
- Try around different types of embedding models, LLM models, chunk strategies
- Provide retrieval functionality as a tool for the LLM so that it can use it the way it wants
- Prompt the LLM to use better queries. For example it can turn the question
Who is the founder?intoFounder of CrawlChatfor better quality of retrieval.
Summary
It is not possible to just give entiry company documents to LLM because of context window and other problems. Going with the first principals, we index the documents using Embedding models and turn them into Vectors so that we can store and retrieve symantically relevant chunks later. We also create vectors for the query and find the best matching chunks from the Vector database. Finally we pass the matching chunk texts and query to LLMs and ask them to answer the question. Hope this gave you an high level understand of the RAG workflow at core. Cheers!